Happiness Project
Andy Lee
1 Introduction
The data was collected from Gallup World Poll. Their survey consisted of questions that asked participants to rank their own life on a Cantril ladder on a scale from 1 to 10, 10 being the best ideal way of living and 0 being the worst. This data set focuses on the happiness score of each country, which ranges from 0 to 10. Each country is ranked based on that averaged happiness score for participants. The team recorded scores for these factors: economy or GDP per Capita, family or social support, health or life expectancy, and freedom to help explain the happiness score of each country. Also, combining the happiness data set with the Death/ Risk factor and Country Profile data sets will achieve a broader understanding of happiness.
Motivation
- Quantify an ambiguous concept of happiness for statistical
analysis
- Derive insights on which factors affect happiness on a global scale
Analysis Summary
Descriptive Statistics (All Three Data Sets):
- Demonstrate the survey results of happiness across the world by
using diverse visualizations
- Observe how happiness scores differ by country and regions
- Find meaningful correlations among the variables
Regression Analysis:
- Compare different regression models by visualizing best fit &
residual plots
- Derive insights into the relationship within variables
Cluster Analysis:
- By using K-means and Hierarchical methods, cluster the data in a continental scope
library(socviz)
library(lubridate)
library(geofacet)
library(ggthemes)
library(ggrepel)
library(ggridges)
library(plyr)
library(skimr)
library(tidyverse)
library(gganimate)
library(plotly)
library(stargazer) # regression tables
library(ggstatsplot)
library(corrr)
library(moderndive)
theme_set(theme_classic())2 Data Wrangling
2.1 Happiness Data
# Read 2015 Data
h15 <- read_csv("Happiness_Data/2015.csv")
h15 <- h15 %>%
dplyr::mutate(Year = 2015) %>%
dplyr::rename(H_rank=`Happiness Rank`, # Modify variable names
H_score = `Happiness Score`,
GDP=`Economy (GDP per Capita)`,
Health=`Health (Life Expectancy)`,
Trust=`Trust (Government Corruption)`,
SE=`Standard Error`,
dystopia_res = `Dystopia Residual`)
# Read 2016 Data
h16 <- read_csv("Happiness_Data/2016.csv")
h16 <- h16 %>%
dplyr::mutate(Year = 2016,
`Standard Error` = (`Upper Confidence Interval`-`Lower Confidence Interval`)/3.92) %>%
# SE = (upper limit – lower limit) / 3.92.
# This is for 95% CI
dplyr::select(-c(`Upper Confidence Interval`,`Lower Confidence Interval`)) %>%
dplyr::rename(H_rank=`Happiness Rank`, # Modify variable names
H_score = `Happiness Score`,
GDP=`Economy (GDP per Capita)`,
Health=`Health (Life Expectancy)`,
Trust=`Trust (Government Corruption)`,
SE=`Standard Error`,
dystopia_res = `Dystopia Residual`)
# Since we don't have a variable 'Region' starting from 2017, we will create it for
# each year
h_regions <- dplyr::select(h16, Country, Region)
# Read 2017 Data
h17 <- read_csv("Happiness_Data/2017.csv")
h17 <- h17 %>%
dplyr::mutate(Year = 2017,
`Standard Error` = (`Whisker.high`-`Whisker.low`)/3.92,) %>%
merge(h_regions,by="Country", all.x=T) %>%
dplyr::select(-c(`Whisker.high`,`Whisker.low`)) %>%
dplyr::rename(H_rank=`Happiness.Rank`, # Modify variable names
H_score = Happiness.Score,
GDP=Economy..GDP.per.Capita.,
Health=Health..Life.Expectancy.,
Trust=Trust..Government.Corruption.,
SE=`Standard Error`,
dystopia_res = Dystopia.Residual)
# Read 2018 Data
h18 <- read_csv("Happiness_Data/2018.csv")
h18 <- h18 %>%
dplyr::mutate(Year = 2018) %>%
dplyr::rename(H_rank=`Overall rank`, # Modify variable names
H_score = `Score`,
GDP=`GDP per capita`,
Country = `Country or region`,
Health=`Healthy life expectancy`,
Trust=`Perceptions of corruption`,
Freedom = `Freedom to make life choices`,
Family = `Social support`) %>%
merge(h_regions,by="Country", all.x=T) %>%
dplyr::mutate(dystopia_res = H_score - (GDP + Family + Health + Freedom + Generosity + as.numeric(Trust)))
# Read 2019 Data
h19 <- read_csv("Happiness_Data/2019.csv")
h19 <- h19 %>%
dplyr::mutate(Year = 2019) %>%
dplyr::rename(H_rank=`Overall rank`, # Modify variable names
H_score = `Score`,
GDP=`GDP per capita`,
Country = `Country or region`,
Health=`Healthy life expectancy`,
Trust=`Perceptions of corruption`,
Freedom = `Freedom to make life choices`,
Family = `Social support`) %>%
merge(h_regions,by="Country", all.x=T) %>%
dplyr::mutate(dystopia_res = H_score -
(GDP + Family + Health + Freedom + Generosity + as.numeric(Trust)))
# Combine all data into all_dat
h_alldat <- tibble(rbind.fill(h15,h16,h17,h18,h19))
# Create Continent Variable
h_alldat <- h_alldat %>%
dplyr::mutate(Country = as.factor(tolower(Country)),
Region = case_when(
grepl('central african republic', as.character(Country)) ~ "Middle East and Northern Africa",
grepl('s.a.r.', as.character(Country)) ~ "Southeastern Asia",
grepl('lesotho', as.character(Country)) ~ "Sub-Saharan Africa",
grepl('mozambique', as.character(Country)) ~ "Sub-Saharan Africa",
grepl('taiwan province', as.character(Country)) ~ "Southeastern Asia",
grepl('cyprus', as.character(Country)) ~ "Central and Eastern Europe",
grepl('tobago', as.character(Country)) ~ "Latin America and Caribbean",
grepl('gambia', as.character(Country)) ~ "Sub-Saharan Africa",
grepl('macedonia', as.character(Country)) ~ "Central and Eastern Europe",
grepl('swaziland', as.character(Country)) ~ "Sub-Saharan Africa",
TRUE ~ Region
),
Continent = case_when(
grepl('Europe', as.character(Region)) ~ "Europe",
grepl('Latin', as.character(Region)) ~ "South America",
grepl('Australia', as.character(Region)) ~ "Oceania",
grepl('Middle East', as.character(Region)) ~ "Asia",
grepl('Africa', as.character(Region)) ~ "Africa",
grepl('Asia', as.character(Region)) ~ "Asia",
grepl('North America', as.character(Region)) ~ "North America"),
Region = as.factor(Region))
col_names = colnames(h_alldat)
rmarkdown::paged_table(h_alldat)Data Descriptions:
Variable Names: Country, Region, H_rank, H_score, SE, GDP, Family, Health, Freedom, Trust, Generosity, dystopia_res, Year, Continent
Years: 2015 ~ 2019
Countries #: 169
Regions # : 10
2.2 Death and Risk Factors Data
# Read data in
death_dat <- read_csv('/Volumes/Programming/AndyLeeProjects.github.io/Happiness_Data/number-of-deaths-by-risk-factor.csv')
death_dat <- death_dat %>%
filter(Year >= 2015) %>%
rename(Country = Entity) %>%
mutate(Country = tolower(Country)) %>%
arrange(Year) %>%
rename(unsafe_water = `Unsafe water source`,
unsafe_sanitation = `Unsafe sanitation`,
alcohol_use = `Alcohol use`,
drug_use = `Drug use`)
rmarkdown::paged_table(data.frame(colnames(death_dat)))Data Descriptions: Provides different causes of deaths and risk factors starting from 2015 to 2017
Total Variable #: 31
Years: 2015 ~ 2017
2.3 Country Profile UN Data
country_profile <- read_csv('/Volumes/Programming/AndyLeeProjects.github.io/Happiness_Data/kiva_country_profile_variables.csv')
country_profile <- country_profile %>%
select(-c(`GDP per capita (current US$)`)) %>%
dplyr::mutate(country = tolower(country)) %>%
dplyr::rename(Country = country,
Life_expectancy = `Life expectancy at birth (females/males, years)`,
Urban_pop = `Urban population (% of total population)`,
Phone_subscriptions = `Mobile-cellular subscriptions (per 100 inhabitants)...41`,
Employment_rate = `Employment: Services (% of employed)`,
GVA_services = `Economy: Services and other activity (% of GVA)`,
Infant_mortality = `Infant mortality rate (per 1000 live births`,
Age_distribution = `Population age distribution (0-14 / 60+ years, %)`,
Fertility_rate = `Fertility rate, total (live births per woman)`,
Sanitation_facilities = `Pop. using improved sanitation facilities (urban/rural, %)`,
Urban_pop_growthrate = `Urban population growth rate (average annual %)`,
GVA_agriculture = `Economy: Agriculture (% of GVA)`,
Pop_growthRate = `Population growth rate (average annual %)`,
Energy_production = `Energy production, primary (Petajoules)`
) %>%
separate(Life_expectancy, c('Life_expectancy_F','Life_expectancy_M'), sep = "/") %>%
separate(Age_distribution, c('Age_distribution_below14','Age_distribution_above60'), sep = "/") %>%
dplyr::select(-c(Region)) %>%
mutate(Life_expectancy_F = as.numeric(Life_expectancy_F),
Life_expectancy_M = as.numeric(Life_expectancy_M),
Life_expectancy_F = case_when(
Life_expectancy_F < quantile(Life_expectancy_F,.66)[[1]] &
Life_expectancy_F > quantile(Life_expectancy_F,.33)[[1]]~ "Medium Life Expectancy",
Life_expectancy_F < quantile(Life_expectancy_F,.33)[[1]] ~ "Low Life Expectancy",
quantile(Life_expectancy_F,.66)[[1]] < Life_expectancy_F ~ "High Life Expectancy"),
Life_expectancy_M = if_else(Life_expectancy_M < mean(Life_expectancy_M),
"Under Average",
"Above Average"),
Age_distribution_below14 = as.numeric(Age_distribution_below14),
Age_distribution_above60 = as.numeric(Age_distribution_above60),
Infant_mortality_aboveAVG =
if_else(Infant_mortality > mean(Infant_mortality),
"High Infant Mortality","Low Infant Mortality"),
Sanitation_facilities_level =
if_else(Sanitation_facilities > median(Sanitation_facilities),
"Lower Sanitation Level", "Higher Sanitation Level")) # Change the Life_expectancy variables into categorical variables
# Display Column names of Country Profile Data
rmarkdown::paged_table(data.frame(colnames(country_profile)))# Merge: Happiness & Country Infrastructure Data
h_p_dat <- merge(h_alldat, country_profile, by = "Country")
save(h_p_dat, file = '/Volumes/Programming/AndyLeeProjects.github.io/Shiny_Happiness/h_p_dat.RData')
# Merge: Happiness & Death/ Risk factors Data
h_d_dat <- merge(h_alldat, death_dat, by = c("Country","Year"))Data Descriptions: Provides countries’ profile data including geographic, population, economic, educational, environmental, etc.
Total Variable #: 52
3 Happiness Data Analysis
3.1 Column Names
3.2 TOP 10 AVG Hppiness Scores
# Get Top 10 mean of happiness rank from 2015 ~ 2019
top_10 <- h_alldat %>%
group_by(Country) %>%
dplyr::summarise(mean_rank = mean(H_rank)) %>%
arrange(mean_rank) %>%
filter(mean_rank <= 10)
rmarkdown::paged_table(top_10)
3.3 Boxplot of H_Scores by Regions
ggplot(dplyr::filter(h_alldat, Region != "NA")) +
geom_boxplot(aes(x = H_score, y=reorder(Region, H_score), color = Region))+
theme_classic() +
theme(legend.position = "None") +
labs(x = "Happiness Scores", y = "Regions")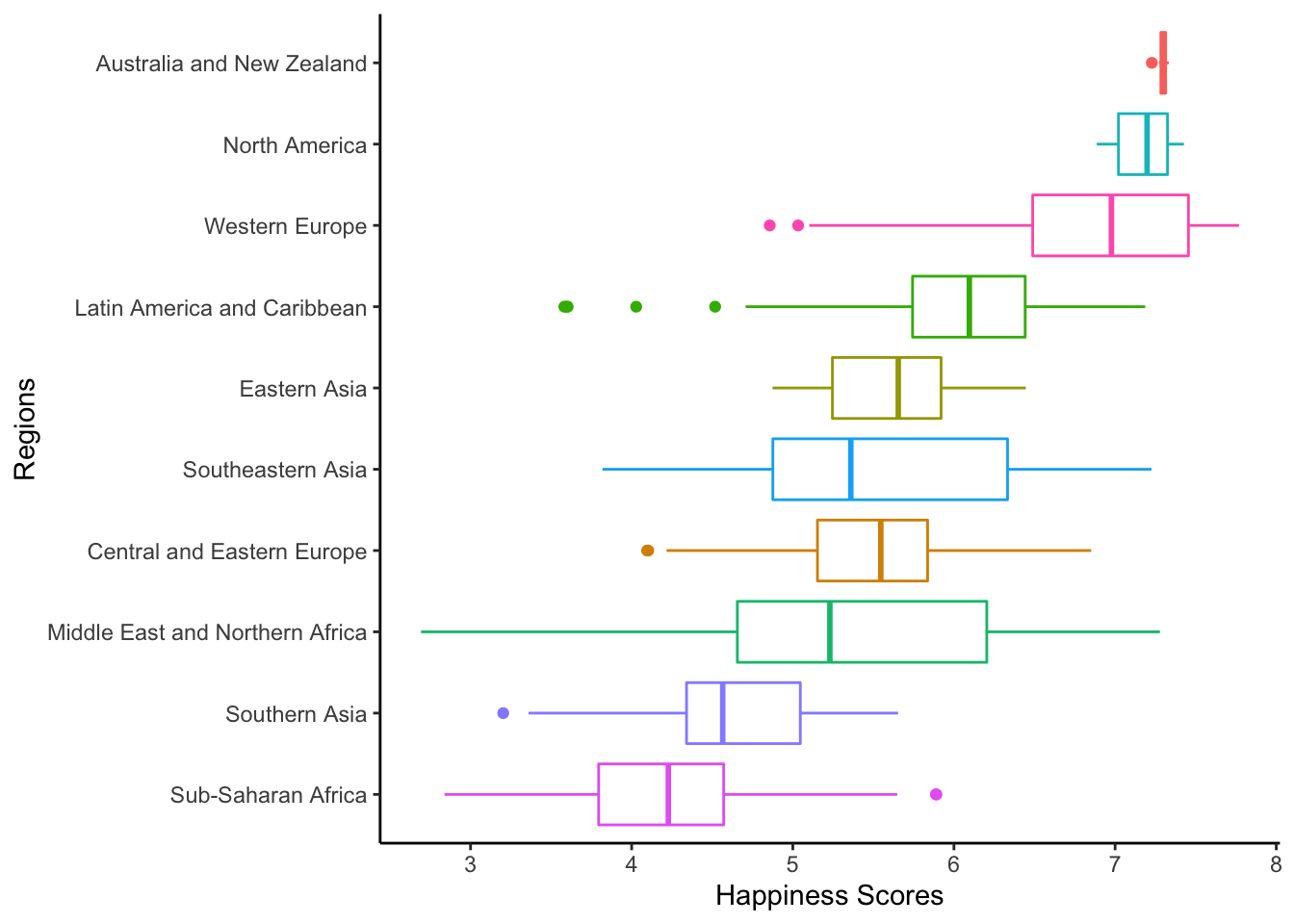
3.4 H_Scores vs GDP
ggplot(dplyr::filter(h_alldat, Region != "NA"), aes(x = GDP, y=H_score, color = Region)) +
geom_point() +
theme_classic()+
labs(title = "Happiness Scores vs GDP by Region\n")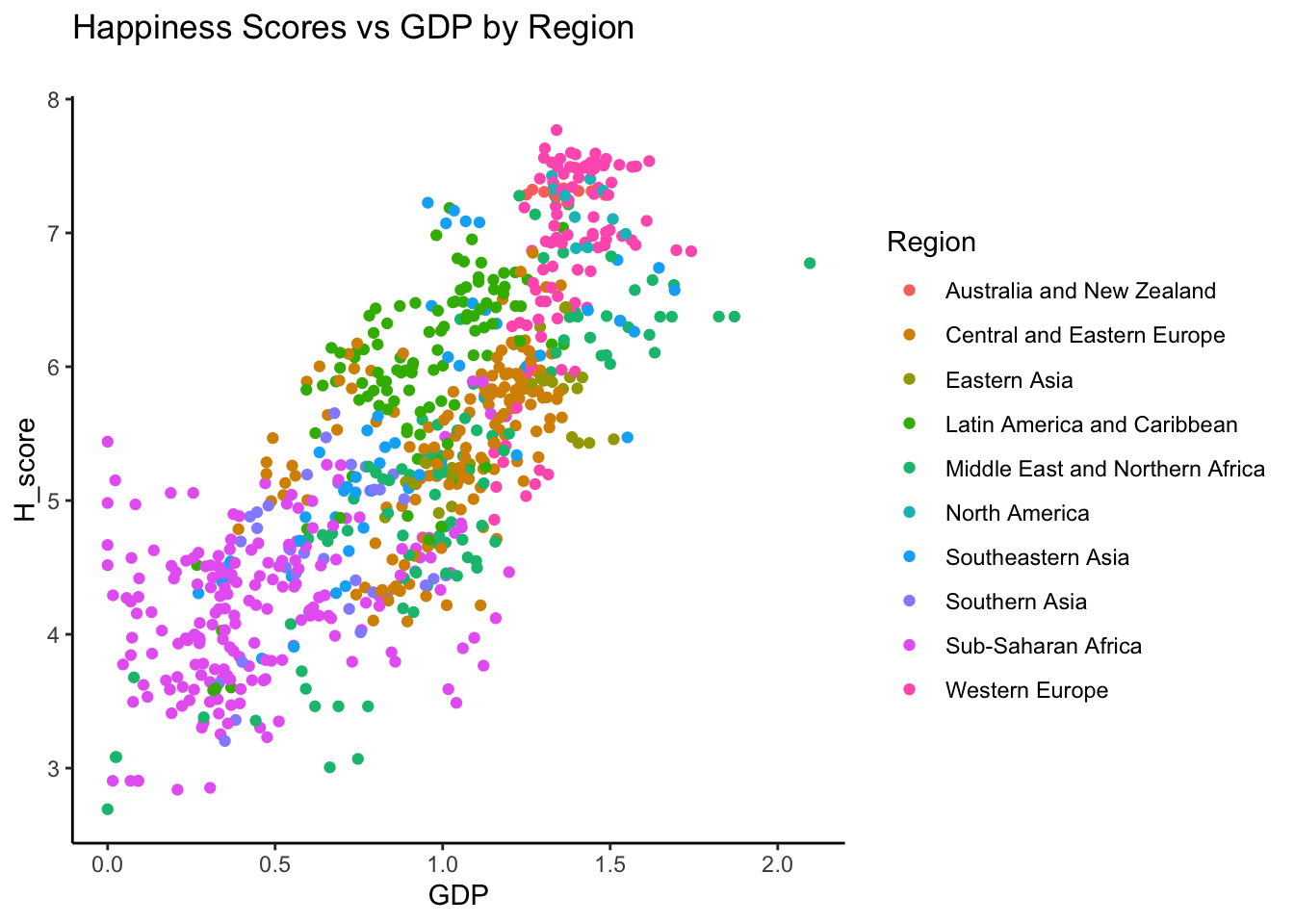
3.5 H_Scores vs GDP: Animation
base <- h_alldat %>%
plot_ly(x = ~GDP, y = ~H_score,
text = ~Country, hoverinfo = "text",
width = 800, height = 500, size = 2)
base %>%
add_markers(color = ~Region, frame = ~Year, ids = ~Country) %>%
animation_opts(1000, easing = "elastic", redraw = FALSE) %>%
animation_slider(
currentvalue = list(prefix = "YEAR ", font = list(color="red"))
)
3.6 World Map by H_Scores
world_map <- map_data("world")
world <- world_map %>%
dplyr::rename(Country = region) %>%
dplyr::mutate(Country = str_to_lower(Country),
Country = ifelse(
Country == "usa",
"united states", Country),
Country = ifelse(
Country == "democratic republic of the congo",
"congo (kinshasa)", Country),
Country = ifelse(
Country == "republic of congo",
"congo (brazzaville)", Country),
Country = as.factor(Country))
h_alldat_world <- left_join(h_alldat, world, by = "Country",all.x=TRUE)
p <- ggplot(h_alldat_world, aes(long, lat, group = group,
fill = H_score,
frame = Year))+
geom_polygon(na.rm = TRUE)+
scale_fill_gradient(low = "white", high = "#FD8104", na.value = NA) +
theme_map()
p %>%
plotly::ggplotly() %>%
animation_opts(1000, easing = "elastic",transition = 0, redraw = FALSE)